
Federated Learning Not 101 - FL0
Federated Learning Not 101 - FL0
Some early papers on Federated Learning

This will be the first in the series of blog posts around Federated Learning. Today I am trying to summarize the paper - “Applied Federated Learning - Improving Google keyboard query suggestions” which was published by the good folks at Google.
Federated learning - I quote the paper - “Federated learning is a distributed form of machine learning where both the training data and model training are decentralized.”
While federated learning has been around for some time, there are definitely areas where development is still needed as far as the paradigm goes. The paper covers the usage of federated learning to improve the Google Keyboard suggestion(gboard suggestions). In a privacy first environment, Federated learning provides a way to train models on the users device while aggregating the parameter estimates on a centralized server. Loosely speaking, the app owner is able to give a good experience to the user without looking/storing the consumer data. This is a huge plus in a world where bad actors are always trying to take advantage of consumer data. FL is an ideal way for an application such as gboard as it give a privacy first and low latency way to give great consumer experience. No consumer would like Google or anyone to look at what you are exactly typing all the time. The use case being discussed here is search query suggestions. Someone types - “Let’s eat a Charlie’s” - This may display a web query suggestion for nearby restaurants with that name. Filtering of the query suggestions happens through the baseline model with an additional triggering model trained with FL.
There is a wealth of data available on device which the user might not want to expose to a company. FL enables an infrastructure paradigm which enables usage of such data in a privacy first way. An ideal place for application of FL would have:-
The task labels don’t require human labelers but are naturally derived from user interaction.
The training data is privacy sensitive.
The training data is too large to be feasibly collected centrally
Federated Averaging - In a series of rounds, a set of devices are chosen to download the central model from the central server and further train/tune the model on local data. The difference between the final parameters and initially sent parameters are sent back to the server for accumulating them into the global model.
FL can guarantee even higher levels of privacy using secure aggregation and differential privacy techniques which was not implemented by Google then.
System Description - Training data consists of tuples(features, label) stored in an on-device cache. Features are a combination of query and context. Label is the associated user action. This data is used for on-device training and evaluation of models provided by the server. The requirement to not impact user experience or mobile data usage is met through Android’s job scheduler to schedule background jobs which run in a separate unix process when the device is on charging, idle and connected to an unmetered network.
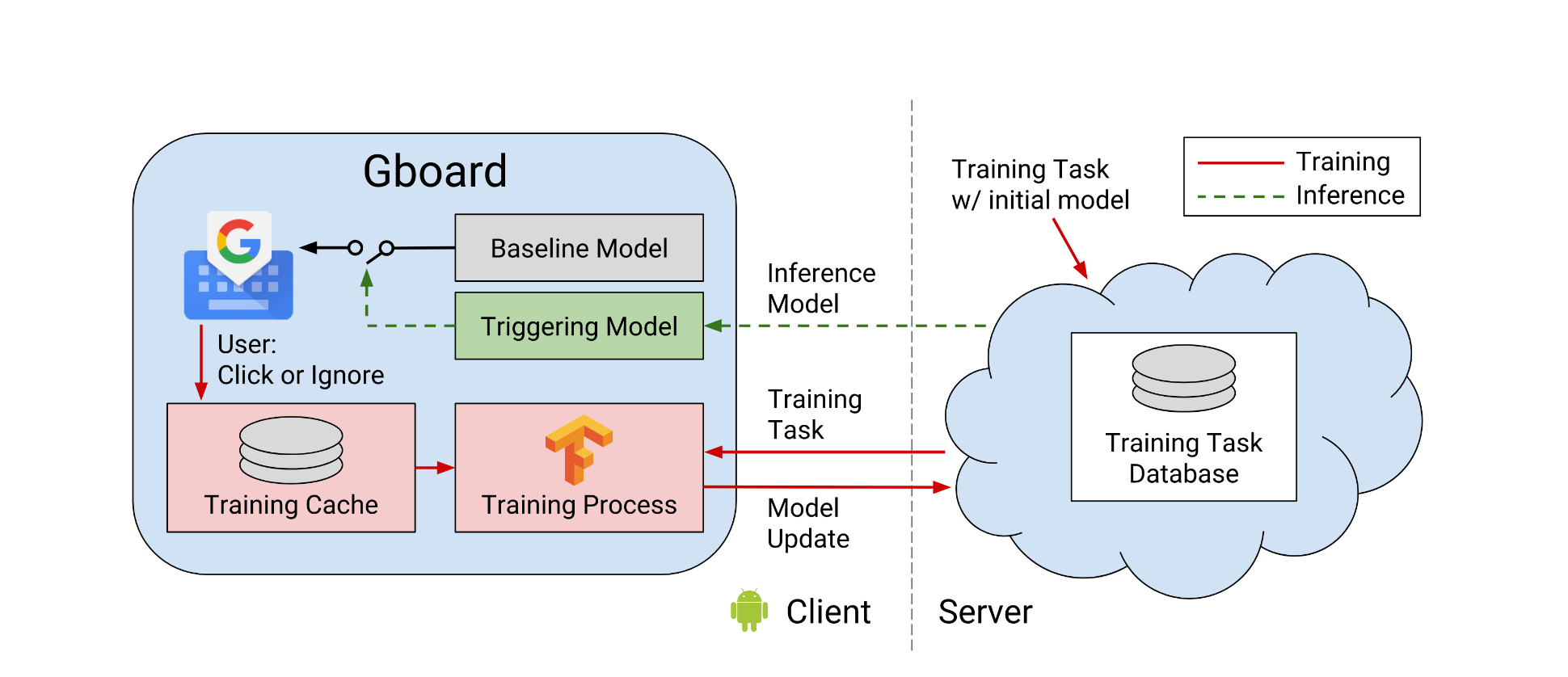
Two notable points mentioned here are:-
Load across multiple devices is balanced by putting a minimum delay after which a client checks in for being a part of the population which will be used for training
Evaluation tasks are also performed by the devices. A minimum threshold performance is monitored and upon convergence a checkpoint is created upon deployment of the updated model
Model architecture -
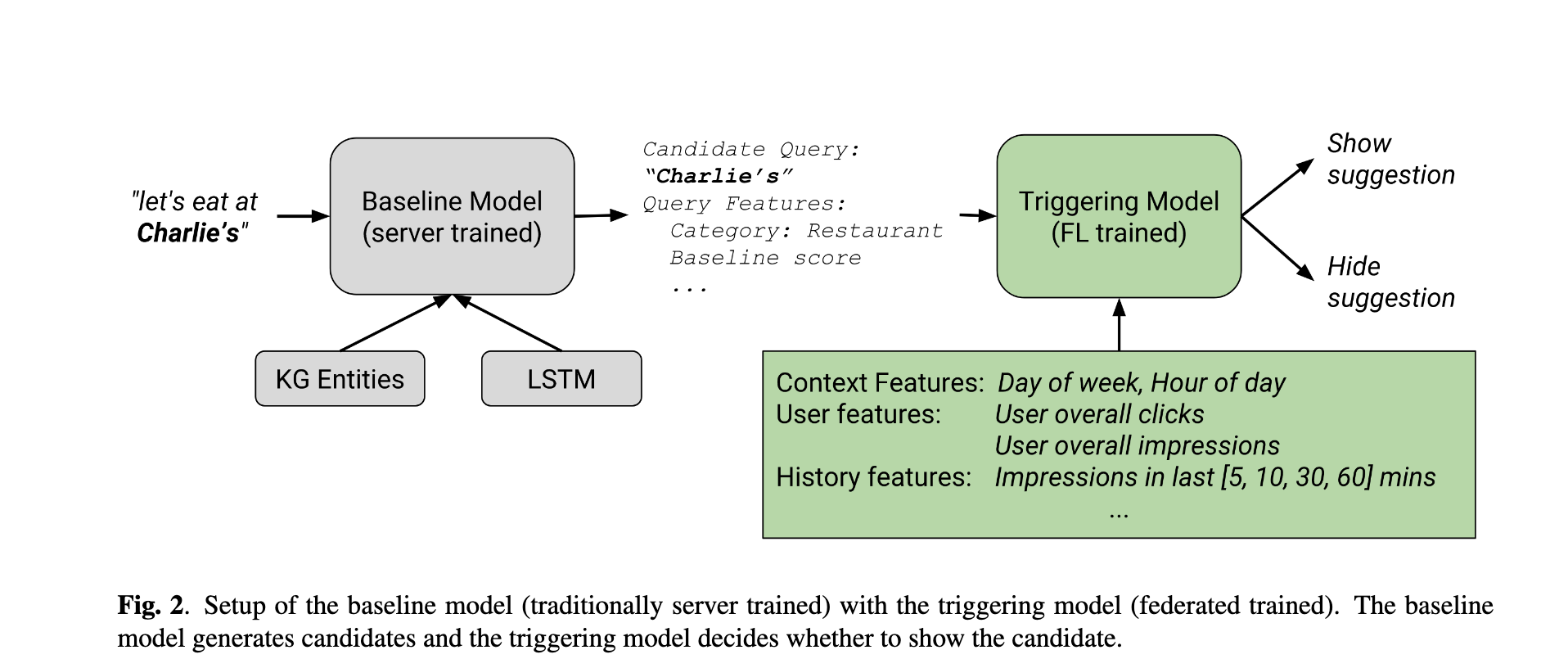
Baseline model for query suggestion is trained offline in a traditional server based ML technique. Query generation candidates are generated by matching user input to an on-device subset of Google Knowledge Graph. It then scores the suggestions using a LSTM trained on an offline corpus of chat data to score the candidates. This LSTM is trained to predicted the KG category of a word in a sentence and returns higher scores when the KG category of the query candidate matches the expected category.
The on device training is expected to improve over the baseline model by making use of user clicks and interactions - Signals which are available on-device for federated training.
Triggering Model - The job of the triggering model is to take the suggested query candidate from the baseline model, and determine if the suggestion should be shown to the user. The model in this case is a Logistic Regression Model. Some of the features used are:-
Past clicks and impressions (at KG category level)
Baseline Score - Output of the baseline model
Day of the week, Hour of the day
The model was forced to be trained when on wifi, idle,and on charging. There were other conditions such as memory requirements on the device, language restrictions, count of minimum clients, and some others.
Federated training - The training was supposed to happen only for en-US and en-CA users but some countries like India also have en-US locale and hence some amount of skew is seen on such devices because of worse network conditions and different behavior. The training seems to be way faster during night because of obvious reasons around people putting their devices on charge in the night. The losses would increase in the day time because of Indian devices with drift reporting their losses during the day time (Night in India).
Model debugging without training example access - During model development, synthetically generated proxy data was used to validate the model architecture to select ballparks for basic hyperparameters learning rates. There was also end to end testing using handful of realistic hand - constructed and donated examples. Logistic regressions are easy to interpret via the direct examination of weights.
While, there was some delta between the expected CTR vs the actual CTR’s, but the model’s overall performed better then the server only models. Some other observations have been made about the model drifts and can be read in the paper.
Hey Arkid, great post! It’s nice that you have revived activity on Substack. Would you mind sharing your email with me? I’m super interested in working in your team, it’s the exact kind of roles + team I’m looking for myself. I’m currently a grad student at University of Maryland, and have few years of experience under my belt.
I want to share my quick background and maybe take your advice to navigate my career. I hope my request if not to straightforward. :)